
Currently, I’m working on re-building my database and models. In this series I will take you through the process. The aim is to be as transparent and precise as possible. I will share all my code and all my files for everyone to use. Hopefully, this can be helpful in getting more people into hockey and hockey analytics.
I like to think that one of my biggest strengths is my ability to explain complex matters in an easy-to-understand manner. The goal is to write a series which everyone can follow – Even without any pre-coding experience.
Previous articles in the Series:
Expected Goals – from a philosophical standpoint
What is an xG model, how do you build an xG model, and why do you need an xG model? These are important questions to ask before diving into model-building.
What are Expected Goals?
Let’s start with the “What” – What is xG really? Here’s my broad definition:
“Expected Goals is the estimated number of goals based on a set of variables.”
All xG models I’ve seen in hockey haven been shot based. Meaning it’s an estimated value of each shot or a goal probability for each shot. However, I don’t necessarily think xG models should be limited to only shots. That’s why I’m using the broad definition of expected goals.
With the public data available we’re forced to base our xG models on shots. Though, with proprietary data you could possibly take a different route. I know that even the private xG models are shot-based, but I believe you could be more innovative with your approach.
The most obvious alternative would be to build a possession-based xG model – to create an estimate of what each possession is worth. So, instead of looking at shots created you would look at possessions created in dangerous areas. This would allow you to estimate the value when a possession starts and compare it to the value when the possession ends. Did the player add or lose xG through his possession?
You could also better describe defensive value. A possession breaking defensive event would be the difference between the opponent having possession of the puck and your team having possession of the puck.
How do you build an xG model?
That leads us to the second question. How do you build an expected goals model? If you’re building a shot-based model, then it’s relatively simple. Every shot can either result in a goal (1) or no goal (0). Those are the only two options. Then we just need to determine the probability of it being a goal.
When you have a Binomial distribution (only two possible outcomes), then you would typically use logistic regression to build your model (more on logistic regression below).
Let’s also discuss the hypothetical possession-based model. In that case we would need to estimate the chance of a given possession leading to a goal for, a goal against or no goal. In other words, there would be three possible outcomes.
My approach would be to look at a timeframe (perhaps 15 seconds). Is there a goal against (-1), a goal for (+1) or no goal (0) in that timeframe from the start of the possession?
If a goal is scored or the period ends, then the timeframe ends. So, there can’t be more than one goal scored. I don’t think the timeframe should end whenever there’s a stoppage. Certain possessions will for example lead to more icings and that should be included in the model. I hope this makes sense.
Why do you need an xG model?
This leads us to the third and final question. Why do we need xG models? What are the purposes of the model(s)?
Let me start by saying I think the name expected goals is somewhat misleading. It leads us to believe that the only purpose of xG is to predict future goals. I think estimated goals would have been a better name.
It’s very important to understand the “Why”. You need to build/choose the xG model based on the questions you want answers to.
One of the ongoing discussions is whether or not you should include shooter talent in the xG model. It makes sense that a shot by Alex Ovechkin has a higher goal probability than a shot by Adam Pelech… But if the purpose is to describe shooter performance, then we can’t include shooter talent in the model, because that’s the very thing we’re trying to determine.
Generally, it’s important to understand the difference between descriptive modelling and predictive modelling. Do we want to describe past events, or do we want to predict future events?
So, probably one xG model isn’t enough. However, expected goals is often considered a single metric like fenwick or corsi, when in fact it can be many different things based on the input variables.
Here are some of the things xG can be used for and some modelling considerations:
- Describe shooter performance (goals scored above expected) – The model should be fenwick- or corsi-based because hitting the net and not being blocked is a shooter skill.
- Describe goaltender performance (GSAx) – Should only include shots on net, as I don’t think we should credit goaltenders for shot misses.
- Describe shot creation/prevention (Think “Deserve To Win o’Meter” or xGF%) – Should be a fenwick- or corsi-based model and you should exclude empty net shots, as they will skew the data (or look at 5v5 data only).
- Predict future results/goals – Should be a fenwick- or corsi-based model, and some the variables might need to be weighed slightly differently. I once saw some research that removing rebound shots increases the predictive power of an xG model. Probably because rebound shots typically have very high xG values but are still somewhat random.
- Possession value added – If we were able to build a possession-based model, then we could calculate possession value added. How much value a player provides through his puck possessions.
Linear regression vs Logistic regression
This won’t be a complex mathematical explanation, but just a basic comparison between a linear regression model and a logistic regression model.
In a linear regression model, you’re trying to fit the best line based on n independent variables (x1, x2,…, xn). In the formula below a0 is the intercept and a1 to an are the weights or coefficients of the independent variables:

This could for instance be something like Standings points (y) and team goal differential (x1). Here you would expect a strong linear correlation.
In a logistic regression model, you’re not trying to fit the best line but instead you’re trying to fit the best Sigmoid curve. This makes sense when you only have two possible outcomes: goal or no goal (1 or 0).

In this case the formula looks different yet similar. We still have independent variables (x1 to xn), the intercept a0 and weights (a1 to an).
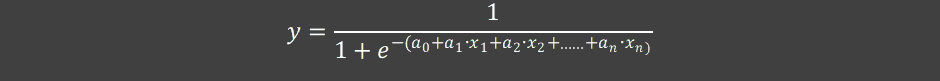
This is important to understand when we apply the coefficients/weights to the dataset in the last step of this article.
Preparing the data in MySQL
Now that we have the theoretical stuff out of the way, we can get started with the actual model building. The first step is to prepare our data for statistical modelling. In the previous article we created the table PBPData_before_xG with all the relevant information. From there we can create the datasets we need to build our models.
We are going to construct two xG models – One that is fenwick-based (xG_F) and one that is shot-on-net-based (xG_S). We will also need to isolate all empty net fenwick shots, so we can build an empty net model.
Here’s the SQL code:
https://github.com/HockeySkytte/HockeySkytte/blob/main/NHL_Prepare_data_for_xG_modelling.sql
Building the xG models
So, we are going to build 3 logistic regression models in Python:
- Model of all non empty-net unblocked shots.
- Model of all non empty-net shots on net.
- Model of all empty-net unblocked shots.
# Import the relevant packages - Not all are used here.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
import numpy as np
from sklearn.metrics import log_loss
# Load data from the CSV file
df = pd.read_csv(r"C:\ProgramData\MySQL\MySQL Server 8.0\Data\public\xG_Model_F.csv", )
# The Goal column will be our dependent variable (y)
y = df["Goal"]
# Create dummie columns for the categorial independent variables. They have distinct values.
X1 = df[["shotType","StrengthState", "LastEvent", "Season", "RinkVenue"]]
X1 = X1.astype(str)
X1 = pd.get_dummies(X1)
X1 = X1.astype(int)
# Create a dataframe with the continuous independent variables + EventIndex as the key column
X2 = df[["EventIndex", "ShotDistance", "ShotAngle"]]
# Join all variables to one dataframe
X = X2.join(X1)
# The data is split into a test set (30%) and a train set (70%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
# The EventIndex column is just our key column needed later on, so we remove the EventIndex column from the train and test set
X_train_Event = X_train[["EventIndex"]]
X_test_Event = X_test[["EventIndex"]]
X_train = X_train.drop(["EventIndex"],axis=1)
X_test = X_test.drop(["EventIndex"],axis=1)
# Run the logistic regression on the training data. We are not fitting the intercept
log_reg = LogisticRegression(max_iter=10000, fit_intercept=False).fit(X_train, y_train)
# Create a dataframe with the test data - EventIndex, prob and goal
prob_test = log_reg.predict_proba(X_test)[:,1]
y_test = y_test.tolist()
X_test_Event = X_test_Event.astype(str)
test = pd.DataFrame()
test['EventIndex'] = X_test_Event['EventIndex'].tolist()
test['prob'] = pd.DataFrame(prob_test.tolist())
test['Goal'] = pd.DataFrame(y_test)
# Create a dataframe with the training data - EventIndex, prob and goal
prob_train = log_reg.predict_proba(X_train)[:,1]
y_train = y_train.tolist()
X_train_Event = X_train_Event.astype(str)
train = pd.DataFrame()
train['EventIndex'] = X_train_Event['EventIndex'].tolist()
train['prob'] = pd.DataFrame(prob_train.tolist())
train['Goal'] = pd.DataFrame(y_train)
# Create a dataframe with the coefficients/weights
coef = pd.DataFrame(zip(X_train.columns, log_reg.coef_.flatten()), columns=['features', 'coef'])
# Write the coefficients, test data and train data to CSV
coef.to_csv('xG_F_Coef.csv', sep=',', encoding='utf-8', index=False, header=True)
test.to_csv('test_F.csv', sep=',', encoding='utf-8', index=False, header=True)
train.to_csv('train_F.csv', sep=',', encoding='utf-8', index=False, header=True)
# Import the relevant packages - Not all are used here.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
import numpy as np
from sklearn.metrics import log_loss
# Load data from the CSV file
df = pd.read_csv(r"C:\ProgramData\MySQL\MySQL Server 8.0\Data\public\xG_Model_S.csv", )
# The Goal column will be our dependent variable (y)
y = df["Goal"]
# Create dummie columns for the categorial independent variables. They have distinct values.
X1 = df[["shotType","StrengthState", "LastEvent", "Season", "RinkVenue"]]
X1 = X1.astype(str)
X1 = pd.get_dummies(X1)
X1 = X1.astype(int)
# Create a dataframe with the continuous independent variables + EventIndex as the key column
X2 = df[["EventIndex", "ShotDistance", "ShotAngle"]]
# Join all variables to one dataframe
X = X2.join(X1)
# The data is split into a test set (30%) and a train set (70%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
# The EventIndex column is just our key column needed later on, so we remove the EventIndex column from the train and test set
X_train_Event = X_train[["EventIndex"]]
X_test_Event = X_test[["EventIndex"]]
X_train = X_train.drop(["EventIndex"],axis=1)
X_test = X_test.drop(["EventIndex"],axis=1)
# Run the logistic regression on the training data. We are not fitting the intercept
log_reg = LogisticRegression(max_iter=10000, fit_intercept=False).fit(X_train, y_train)
# Create a dataframe with the test data - EventIndex, prob and goal
prob_test = log_reg.predict_proba(X_test)[:,1]
y_test = y_test.tolist()
X_test_Event = X_test_Event.astype(str)
test = pd.DataFrame()
test['EventIndex'] = X_test_Event['EventIndex'].tolist()
test['prob'] = pd.DataFrame(prob_test.tolist())
test['Goal'] = pd.DataFrame(y_test)
# Create a dataframe with the training data - EventIndex, prob and goal
prob_train = log_reg.predict_proba(X_train)[:,1]
y_train = y_train.tolist()
X_train_Event = X_train_Event.astype(str)
train = pd.DataFrame()
train['EventIndex'] = X_train_Event['EventIndex'].tolist()
train['prob'] = pd.DataFrame(prob_train.tolist())
train['Goal'] = pd.DataFrame(y_train)
# Create a dataframe with the coefficients/weights
coef = pd.DataFrame(zip(X_train.columns, log_reg.coef_.flatten()), columns=['features', 'coef'])
# Write the coefficients, test data and train data to CSV
coef.to_csv('xG_S_Coef.csv', sep=',', encoding='utf-8', index=False, header=True)
test.to_csv('test_S.csv', sep=',', encoding='utf-8', index=False, header=True)
train.to_csv('train_S.csv', sep=',', encoding='utf-8', index=False, header=True)
For the empty-net model we are removing all independent variables except ShotDistance and ShotAngle. We are also adding an intercept.
# Import the relevant packages - Not all are used here.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
import numpy as np
from sklearn.metrics import log_loss
# Load data from the CSV file
df = pd.read_csv(r"C:\ProgramData\MySQL\MySQL Server 8.0\Data\public\xG_Model_F_EN.csv", )
# The Goal column will be our dependent variable (y)
y = df["Goal"]
# The Independent variables are ShotDistance and ShotAngle
X = df[["EventIndex", "ShotDistance", "ShotAngle"]]
# The data is split into a test set (30%) and a train set (70%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
# The EventIndex column is just our key column needed later on, so we remove the EventIndex column from the train and test set
X_train_Event = X_train[["EventIndex"]]
X_test_Event = X_test[["EventIndex"]]
X_train = X_train.drop(["EventIndex"],axis=1)
X_test = X_test.drop(["EventIndex"],axis=1)
# Run the logistic regression on the training data. We are fitting the intercept as well
log_reg = LogisticRegression(max_iter=10000, fit_intercept=True).fit(X_train, y_train)
# Create a dataframe with the test data - EventIndex, prob and goal
prob_test = log_reg.predict_proba(X_test)[:,1]
y_test = y_test.tolist()
X_test_Event = X_test_Event.astype(str)
test = pd.DataFrame()
test['EventIndex'] = X_test_Event['EventIndex'].tolist()
test['prob'] = pd.DataFrame(prob_test.tolist())
test['Goal'] = pd.DataFrame(y_test)
# Create a dataframe with the training data - EventIndex, prob and goal
prob_train = log_reg.predict_proba(X_train)[:,1]
y_train = y_train.tolist()
X_train_Event = X_train_Event.astype(str)
train = pd.DataFrame()
train['EventIndex'] = X_train_Event['EventIndex'].tolist()
train['prob'] = pd.DataFrame(prob_train.tolist())
train['Goal'] = pd.DataFrame(y_train)
# Create a dataframe with the coefficients/weights
coef = pd.DataFrame(zip(X_train.columns, log_reg.coef_.flatten()), columns=['features', 'coef'])
# Write the coefficients, test data and train data to CSV
coef.to_csv('xG_F_EN_Coef.csv', sep=',', encoding='utf-8', index=False, header=True)
test.to_csv('test_F_EN.csv', sep=',', encoding='utf-8', index=False, header=True)
train.to_csv('train_F_EN.csv', sep=',', encoding='utf-8', index=False, header=True)
# Show the intercept
intercept = log_reg.intercept_
intercept
Applying the model on our Event data
Now we have all the coefficients from the 3 models. I’ve simply combined all the coefficients in one table that you can download here:
And with that we can finalize all our tables and write them as CSV files.
Here’s the SQL code:
https://github.com/HockeySkytte/HockeySkytte/blob/main/NHL_Create_the_final_Tables.sql
The tables can be found in the data section on the website or be downloaded right here:
- NHL_Teams
- NHL_Players
- NHL_Schedule
- NHL_Shifts (around 1.7 GB)
- NHL_EventData (around 3 GB)
Things to consider
I’m including RinkVenue (Home team) as a variable. This is to account for Rink bias – It’s for instance well documented that shots in Madison Square Garden used to be tagged way too close to net, so we need to adjust for that. I wrote this article a million years ago:
I’m also including the Season as a variable. If we don’t do this, then we will have seasons where the total xG differentiates quite a bit from the total number of actual goals. I think this is a problem when comparing GSAx across seasons. GSAx should always be in relationship to the average goaltending that specific year.
So, why are there xG differences from year to year? Part of it is the game evolving in ways that the model can’t properly catch (e.g. less point shots and more high danger shots)… But it’s also something like goaltender equipment – When size restrictions were implemented it led to an increase in goals.
However, there are problems with including RinkVenue and Season to the model. For example if we are going use this model for the 2025/2026 season, then we need to estimate the coefficients for the upcoming season. Of course, we could just go with the same as the 2024/2025 season. That’s probably a decent estimation, but it’s still something to be aware of.
Next article – Testing the xG models
In the next article we will run some tests on xG models to see how the models perform – Both in terms of descriptive power and predictive power. How well can the models predict future goals?
Contact
Please reach out if you have comments/questions or if you want to share your own work. I will gladly post it on my platforms.
You can contact me on: hockeystatistics.com@gmail.com

2 thoughts on “Hockey Analytics – Building xG models in Python”